# 常用工具
# 联网搜索
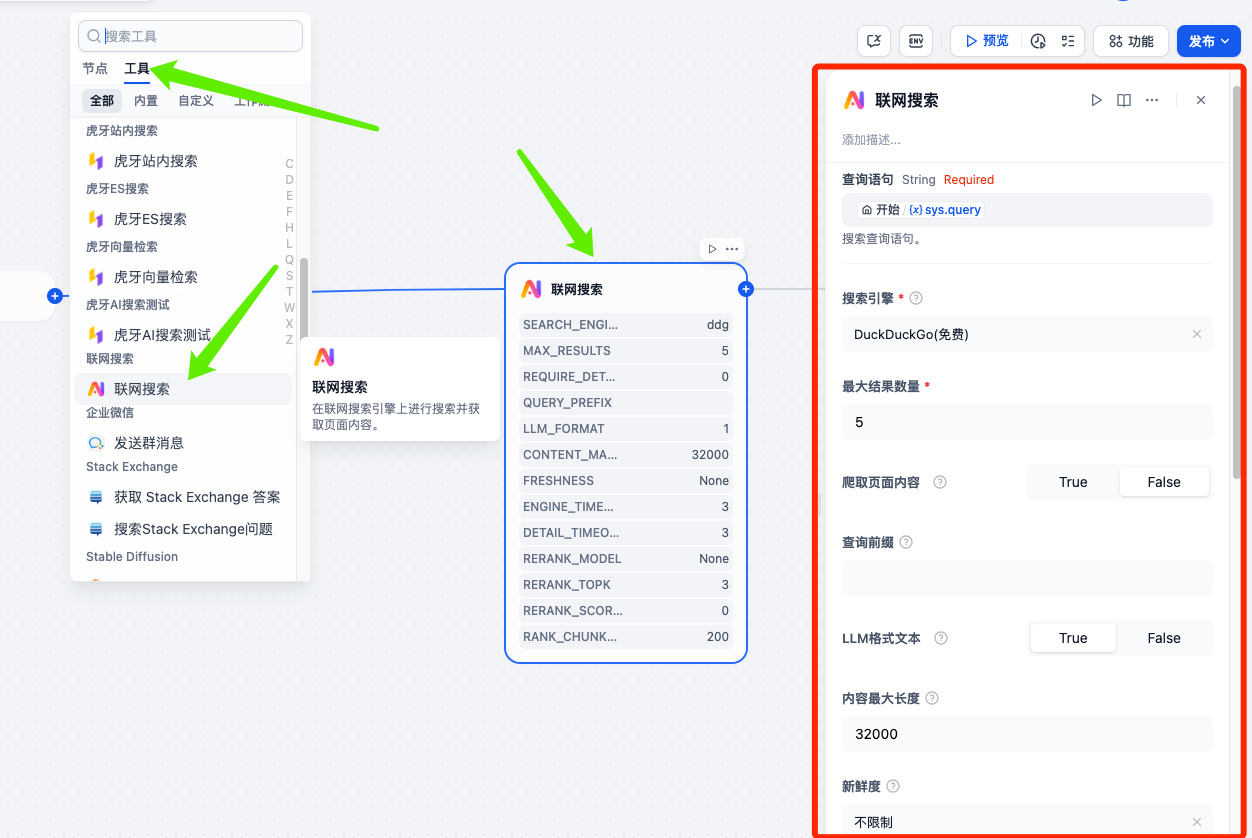
# 用途
用于联网搜索最新信息,支持多种搜索引擎,以及强大的网页内容爬虫能力
# 核心功能
- 通过搜索引擎搜索相关页面,包含页面标题、摘要和页面URL
- 通过开启页面爬取能力,会自动爬取每一个页面详情内容
- 通过开启重排模型,会对爬取的内容做重排,减少冗余无用信息,避免一次性喂进LLM模型太多数据
- query和url详情缓存功能,开启则会缓存query和url,用于同样qeury或url时直接返回之前的结果,提速,当命中缓存时200ms内返回结果
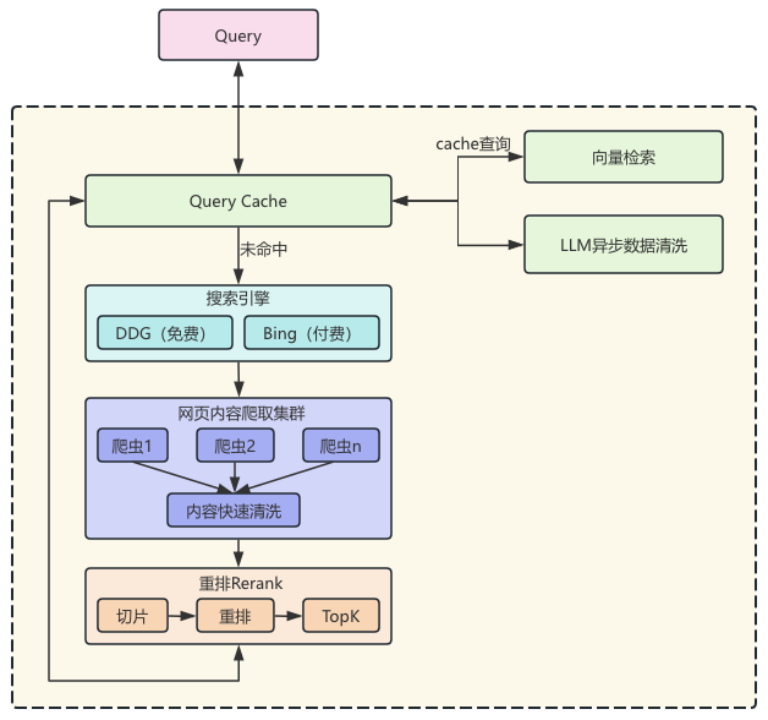
# 主要参数解释
- 搜索引擎:
- bing: 微软bing搜索引擎,需要付费使用,约22RMB/千次请求
- duckduckgo:免费搜索引擎,可免费使用,如需超大规模使用,请提前联系平台
- auto:自动模式,优先使用免费的duckduckgo,在前者遇到故障时,自动使用bing兜底
- 最大结果数:搜索引擎一次返回的最大网页结果数量
- 爬取页面内容:由于搜索引擎默认只提供网页的标题、摘要和URL,如果网页的详情内容,需要单独开启此功能,平台会自动并行爬取页面详情内容
- 查询前缀:可以增加搜索引擎通用参数,比如指定搜索某些网站:site:baike.com,指定多个时:(site:3dmgame.com OR site:qq.com)
- LLM格式文本:开启则直接返回适合喂入LLM的文本,关闭则返回的是object对象,可按需解析
- 内容最大长度:限制返回的最大内容长度,避免返回过长导致无法喂入下一个环境
- 新鲜度:搜索引擎搜索时的时间范围要求,可选天、周、月、年和不限制
- 搜索引擎超时:限制搜索引擎最大不允许超过多少时间,用于某些时延敏感业务时限制时间
- 爬取网页内容超时:限制爬取网页内容超时最大不允许超过多少时间,用于某些时延敏感业务时限制时间
- 禁用QUERY缓存:禁用query缓存功能
- 禁用DETAIL缓存:禁用URL页面详情缓存功能
- 缓存命中率阈值:判断query相似度时,所使用的阈值,当向量检索query时,相似度大于阈值,则判断命中,返回缓存
- 重排模型:做重排时选择的模型,不选择则不开启重排
- 重排TopK:重排后,返回其中TopK的内容,丢弃其它内容,去除冗余杂质
- 重排分数阈值:返回结果中,低于此分数阈值的内容也将丢弃,避免TopK内有低质量内容
- 重排分块大小:将网页详情内容切分一个一个chunk,再去做重排,剔除网页内无用内容,设置chunk大小
# 电子邮件Email
可以在工作流中插入发送邮件节点到邮箱
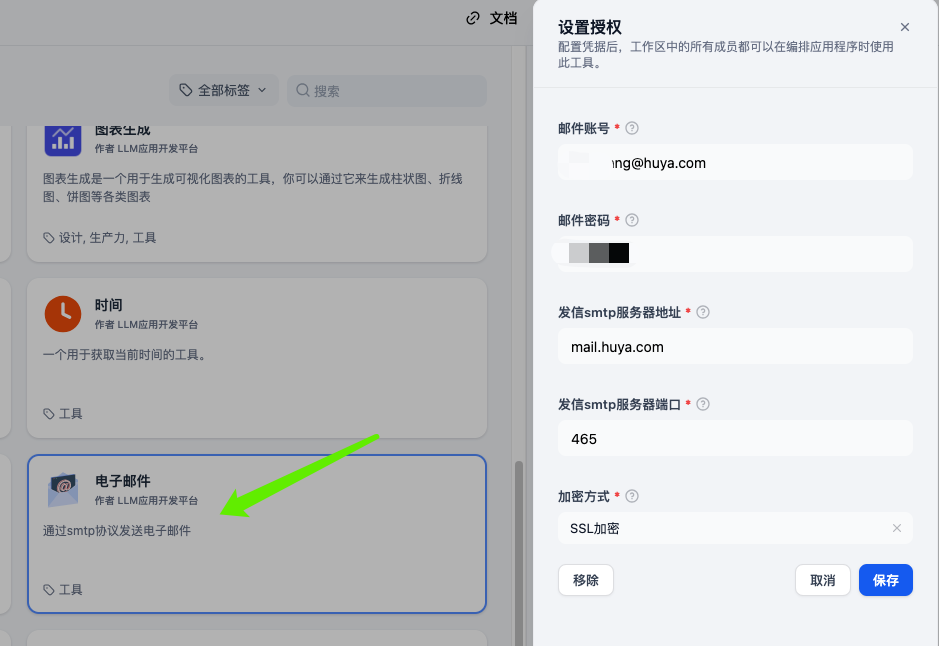
第一步先到先到工具列表中找到电子邮件工具点击授权,填写自己的账号密码,按图设置:
第二步在工作流中找到发送邮件工具,按提示填写:
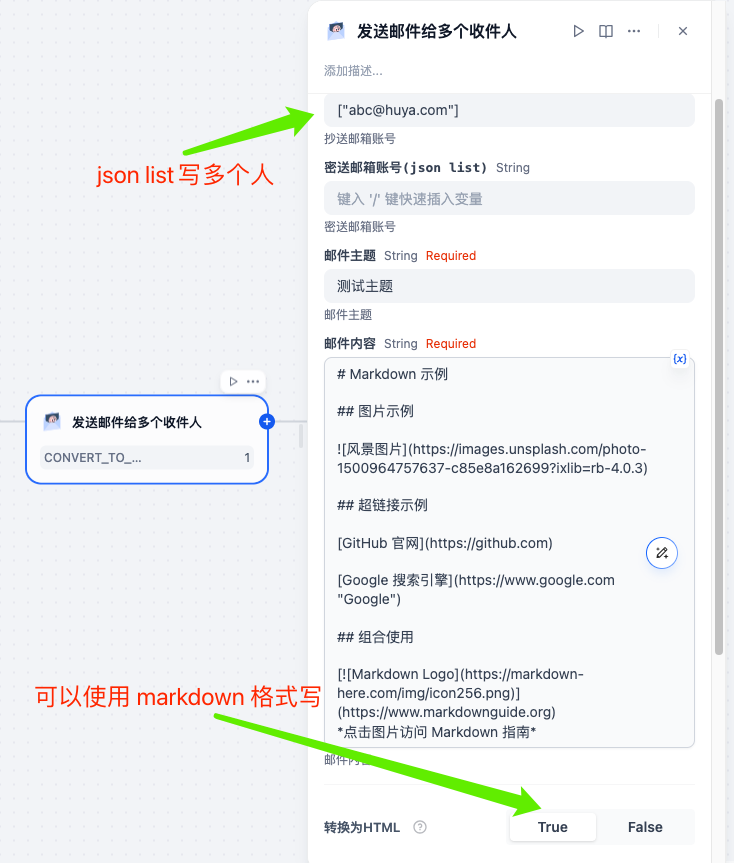
- 使用 json 的列表格式填写多个接收人
- 邮件内容可以使用markdown格式填写,同时要勾选转html,会markdown 内容转为html格式方便邮件显示,当然也可以使用普通文本
# 其它
TODO: 持续更新中