# EFDL
# 1. 介绍
EFDL 全称为 Elastic and Fault-tolerant Deep Learning Framework ,即弹性与容错的深度学习框架。是一个依托于现有框架(如Tensorflow、PyTorch、Horovod)之上,赋予其具备弹性扩缩和节点容错的增强框架。
- 弹性扩缩,充分利用空闲资源,加速训练
- 节点宕机等异常容错,避免任务中断
- 任务的挂起与恢复
- 碎片化调度
常见场景如下:

# 2. 基本原理
 与传统的分布式训练通过一个Launcher启动多个节点的方式不同的是,EFDL采用无主启动方式,利用etcd做服务发现与选举,每个节点都将自己注册至etcd中,利用etcd进行选举,决定各个节点的角色(rank)。
与传统的分布式训练通过一个Launcher启动多个节点的方式不同的是,EFDL采用无主启动方式,利用etcd做服务发现与选举,每个节点都将自己注册至etcd中,利用etcd进行选举,决定各个节点的角色(rank)。
- 在训练过程中,可以随时启动一个新节点,自动注册至etcd中,其它节点通过etcd感知到有新节点加入时,会自动暂停训练,与新节点一起重新选举角色,然后进入继续训练,从而实现扩节点加速训练。
- 在训练过程中,可以随时缩掉一个旧节点,其它节点感知到有节点丢失,会自动重新进入角色选择,然后继续训练,从而实现缩节点,释放部分资源给其它高优先级用途。
- 在扩缩过程中,EFDL的辅助工具会维护权值和参数的暂存和恢复,无需用户关心。
# 3. 使用说明
efdl的弹性扩缩容和容错的逻辑独立于用户的代码,扩缩容的间隔为30分钟以上,用户只需要在托管训练页面以弹性训练的模式启动任务即可。
由于efdl在扩缩容的时候会直接中断并重启训练进程,所以用户的训练代码需要包含断点训练恢复的逻辑,比如根据worker数重置训练参数、定期checkpoint以及启动时从checkpoint恢复训练信息。如果不使用弹性逻辑,为了容错,定期checkpoint以及从checkpoint恢复训练信息的逻辑也是需要的。
# 3.1 多卡训练
efdl内置部分多卡训练框架的环境变量设置。如果你使用多卡训练的话,仅需要使用efdl进行多卡训练的初始化即可,其它代码不用改变。
目前efdl支持以下框架的初始化:
# 3.1.1 horovod
使用原生的horovod也是可以的,使用efdl包可搭配平台方提供的分布式加速框架使用。
# horovod.torch
from efdl.backend.horovod.torch import hvd
# horovod.tensorflow
from efdl.backend.horovod.tensorflow import hvd
# horovod.tensorflow.keras
from efdl.backend.horovod.tensorflow.keras import hvd
hvd.init()
# 3.1.2 torch.ddp
# torch.ddp
import efdl.backend.torch as efdl
efdl.init()
# 3.2 断点恢复工具
为了帮助用户更好地恢复中断的训练,efdl为部分训练框架提供了断点训练恢复的工具。
# 3.2.1 torch
# 3.2.1.1 State
State能够快速缓存训练快照到内存和定期异步持久化远端存储,对训练速度的影响几乎为零。在训练恢复时,能够自动从远端存储拉取训练快照恢复对应的变量。
State预设的参数为model、optimizer、scheduler,后续的kwargs参数为用户定制的用于断点训练恢复用的参数。输入到State的参数都会持久化到训练快照中,可直接通过State.{name}修改和获取值。
State在初始化时会查看远端存储是否有当前任务ID的训练快照,有则拉取快照到本地并恢复参数。所以可能会出现初始化State时输入的是epoch=0,初始化后变成了epoch=10的情况。
# horovod.torch
import efdl.backend.horovod.torch as efdl
# torch.ddp
import efdl.backend.torch as efdl
...
state = efdl.State(model, optimizer, scheduler, epoch=0, step=0, world_size=hvd.size())
State预设的model、optimizer、scheduler参数是非必须的,用户可以直接不输入。考虑到用户代码的model、optimizer和scheduler可能分布在代码不同的地方中,State提供了对应的独立设置函数,方便用户逐个设置。
# horovod.torch
import efdl.backend.horovod.torch as efdl
# torch.ddp
import efdl.backend.torch as efdl
...
state = efdl.State(epoch=0, step=0, world_size=hvd.size())
state.set_and_resotre_model(model)
state.set_and_resotre_optimizer(optimizer)
state.set_and_restore_scheduler(scheduler)
State的训练快照保存需要调用commit()手动触发。如果通过set_commit_interval设置了保存间隔,则会在调用commit()时判断state.step是否满足保存间隔。
import efdl.backend.horovod.torch as efdl
from efdl.backend.horovod.torch import hvd
...
state = efdl.State(model, optimizer, scheduler, epoch=0, step=0, world_size=hvd.size())
state.set_commit_interval(1000)
...
for idx, data in enumerate(dataloader):
...
state.commit()
# 3.2.1.2 DistributedSampler
DistributedSampler在原分布式sampler的基础上提供了内置的数据跳过逻辑。start_index指代需要跳过的数据量。当进行弹性训练时,要结合扩缩前的worker数与扩缩后的worker数重新计算state.step,不然会造成数据缺漏或重复训练。
epoch参数用于设置数据的随机因子,跟原分布式sampler一样。。
# horovod.torch
import efdl.backend.horovod.torch as efdl
# torch.ddp
import efdl.backend.torch as efdl
...
train_sampler = efdl.data.DistributedSampler(train_dataset, epoch=state.epoch, start_index=state.step * args.batch_size)
for state.step, data in enumerate(dataloader, start=state.step):
...
如果数据集构造的代码与State的声明不在同一个地方,可通过DistributedSampler.update函数在主代码更新DistributedSampler的参数。
# horovod.torch
import efdl.backend.horovod.torch as efdl
# torch.ddp
import efdl.backend.torch as efdl
...
train_sampler = efdl.data.DistributedSampler(train_dataset)
...
train_sampler.update(start_index=state.step * train_data_loader.batch_size, epoch=state.epoch,
num_replicas=efdl.get_world_size(), rank=efdl.get_rank())
for state.step, data in enumerate(dataloader, start=state.step):
...
# 3.2.2 tensorflow
TBD:暂时还没有tensorflow的辅助工具,如需要可找我们开发。
# 3.2.3 keras
TBD:暂时还没有keras的辅助工具,如需要可找我们开发。
# 3.3 EFDL实践
从代码修改到平台提交训练
# 3.3.1 PyTorch的EFDL最佳实践
# 3.3.1.1 Pytorch horovod搭配原生工具
使用原生的horovod支持弹性扩缩容以及容错,只需要引入EFDL包进行初始化即可。
为了支持更好地断点训练恢复,需要用户手动保存快照以及恢复快照,可使用torch.load和torch.save方法。
import os
import uuid
import shutil
import torch.nn.functional as F
import torch.optim as optim
import torch.utils.data.distributed
import torchvision.models as models
from torchvision import datasets, transforms
# EFDL:引入EFDL
from efdl.backend.horovod.torch import hvd
hvd.init()
torch.cuda.set_device(hvd.local_rank())
import argparse
parser = argparse.ArgumentParser(description='hvd_pytorch_mnist')
parser.add_argument('--data', type=str, dest='data', default='./data')
parser.add_argument('--lr', type=int, dest='lr', default=0.001)
parser.add_argument('--epoch', type=int, dest='epoch', default=90)
parser.add_argument('--step_size', type=int, dest='step_size', default=30)
parser.add_argument('--log_interval', type=int, dest='log_interval', default=10)
parser.add_argument('--batch_size', type=int, dest='batch_size', default=1)
parser.add_argument('--save_dir', type=str, dest='save_dir', default='./result')
args = parser.parse_args()
epoch_ = args.epoch
lr_ = args.lr
momentum_ = 0.9
step_size = args.step_size
log_interval = args.log_interval
batch_size = args.batch_size
model = models.resnet50(num_classes=10).cuda()
optimizer = optim.SGD(model.parameters(), lr=lr_ * hvd.size(), momentum=momentum_)
optimizer = hvd.DistributedOptimizer(optimizer, named_parameters=model.named_parameters())
scheduler = torch.optim.lr_scheduler.StepLR(optimizer, step_size, gamma=0.1, last_epoch=-1)
# EFDL:快照恢复
start_epoch = 0
if os.path.exists(os.path.join(args.save_dir, "last.pt")):
ckpt = torch.load(os.path.join(args.save_dir, "last.pt"))
start_epoch = ckpt['epoch'] + 1
model.load_state_dict(ckpt['model'])
optimizer.load_state_dict(ckpt['optimizer'])
scheduler.load_state_dict(ckpt['scheduler'])
duplicate_data_path = './data_{}'.format(str(uuid.uuid1()))
shutil.copytree('./data', duplicate_data_path)
train_dataset = \
datasets.MNIST(duplicate_data_path, train=True, download=True,
transform=transforms.Compose([
transforms.Resize((224, 224)),
transforms.Lambda(lambda image: image.convert('RGB')),
transforms.ToTensor(),
transforms.Normalize(mean=[0.485, 0.456, 0.406],
std=[0.229, 0.224, 0.225])
]))
shutil.rmtree(duplicate_data_path)
train_sampler = torch.utils.data.distributed.DistributedSampler(train_dataset, num_replicas=hvd.size(), rank=hvd.rank())
train_loader = torch.utils.data.DataLoader(train_dataset, batch_size=args.batch_size, sampler=train_sampler, pin_memory=True, num_workers=8)
for epoch in range(start_epoch, epoch_):
model.train()
train_sampler.set_epoch(epoch)
for step, (data, target) in enumerate(train_loader):
data, target = data.cuda(), target.cuda()
optimizer.zero_grad()
output = model(data)
loss = F.cross_entropy(output, target)
loss.backward()
optimizer.step()
if step % log_interval == 0:
print('Train Epoch: {} [{}/{} ({:.0f}%)]\tLoss: {:.6f}\tLR: {:.6f}'.format(
epoch, step, len(train_loader),
100.0 * step / len(train_loader), loss.item(), scheduler.get_last_lr()[0]))
scheduler.step()
if not os.path.exists(args.save_dir):
os.makedirs(args.save_dir)
# EFDL:快照保存
last_model_path = os.path.join(args.save_dir, "last.pt")
torch.save({
'epoch': epoch,
'model': model.state_dict(),
'optimizer': optimizer.state_dict(),
'scheduler': scheduler.state_dict()
}, last_model_path)
# 3.3.1.2 Pytorch horovod 搭配efdl工具(推荐)
使用原生的horovod支持弹性扩缩容以及容错,只需要引入EFDL包进行初始化即可。为了支持更好地断点训练恢复,需要用户手动保存快照以及恢复快照,可使用torch.load和torch.save方法。这种断点恢复方案虽然可行,但是问题在不灵活而且很耗时。
为此,efdl提供了断点恢复工具State和DistributedSampler,分别支持内存快照缓存与定时持久化,以及更细粒度的数据读取恢复,具体用法可以参照文档第三章。
import math
import uuid
import shutil
import argparse
import torch.nn.functional as F
import torch.optim as optim
import torch.utils.data.distributed
import torchvision.models as models
from torchvision import datasets, transforms
parser = argparse.ArgumentParser(description='hvd_pytorch_mnist')
parser.add_argument('--data', type=str, dest='data', default='./data')
parser.add_argument('--epoch', type=int, dest='epoch', default=100)
parser.add_argument('--lr', type=int, dest='lr', default=0.001)
parser.add_argument('--step_size', type=int, dest='step_size', default=20)
parser.add_argument('--log_interval', type=int, dest='log_interval', default=10)
parser.add_argument('--batch_size', type=int, dest='batch_size', default=1)
args = parser.parse_args()
# EFDL:引入EFDL
import efdl.backend.horovod.torch as efdl
from efdl.backend.horovod.torch import hvd
hvd.init()
torch.cuda.set_device(hvd.local_rank())
epoch_ = args.epoch
lr_ = args.lr
momentum_ = 0.9
step_size = args.step_size
log_interval = args.log_interval
model = models.resnet50(num_classes=10).cuda()
optimizer = optim.SGD(model.parameters(), lr=lr_ * hvd.size(), momentum=momentum_)
optimizer = hvd.DistributedOptimizer(optimizer, named_parameters=model.named_parameters())
scheduler = torch.optim.lr_scheduler.StepLR(optimizer, step_size, gamma=0.1, last_epoch=-1)
# EFDL:声明efdl.state,用于保存关键变量以及节点间通信
state = efdl.State(model, optimizer, scheduler, epoch=0, step=0, world_size=hvd.size())
state.set_commit_interval(log_interval * 10)
# EFDL:根据环境重新设置相关变量的方法
pre_world_size = state.world_size
state.world_size = hvd.size()
if state.world_size != pre_world_size and state.step != 0:
state.step = math.floor((state.step + 1) * 1.0 * pre_world_size / hvd.size())
duplicate_data_path = '{}_{}'.format(args.data, str(uuid.uuid1()))
shutil.copytree(args.data, duplicate_data_path)
train_dataset = \
datasets.MNIST(duplicate_data_path, train=True, download=True,
transform=transforms.Compose([
transforms.Resize((224, 224)),
transforms.Lambda(lambda image: image.convert('RGB')),
transforms.ToTensor(),
transforms.Normalize(mean=[0.485, 0.456, 0.406],
std=[0.229, 0.224, 0.225])
]))
shutil.rmtree(duplicate_data_path)
# EFDL: 使用efdl的sampler进行dataloader初始化,efdl的sampler可更新数据集分片以及指定迭代的起始位置
train_sampler = efdl.data.DistributedSampler(train_dataset, epoch=state.epoch, start_index=state.step*args.batch_size)
train_loader = torch.utils.data.DataLoader(train_dataset, batch_size=args.batch_size, sampler=train_sampler, pin_memory=True, num_workers=8)
# EFDL: 训练逻辑,epoch和step均与state关联,保证能够继续训练,调用state.commit保存状态
for state.epoch in range(state.epoch, epoch_):
train_sampler.set_epoch(state.epoch)
for state.step, (data, target) in enumerate(train_loader, start=state.step):
data, target = data.cuda(), target.cuda()
optimizer.zero_grad()
output = model(data)
loss = F.cross_entropy(output, target)
loss.backward()
optimizer.step()
if state.step % log_interval == 0:
print('Train Epoch: {} [{}/{} ({:.0f}%)]\tLoss: {:.6f}\tLR: {:.6f}'.format(
state.epoch, state.step, len(train_loader),
100.0 * state.step / len(train_loader), loss.item(), scheduler.get_last_lr()[0]))
state.commit()
state.step = 0
state.commit()
scheduler.step()
# 3.3.1.3 torch.ddp搭配原生工具
使用原生的torch.ddp支持弹性扩缩容以及容错,只需要引入EFDL包进行初始化即可。
为了支持更好地断点训练恢复,需要用户手动保存快照以及恢复快照,可使用torch.load和torch.save方法。
import os
import uuid
import shutil
import torch.nn.functional as F
import torch.optim as optim
import torch.utils.data.distributed
import torchvision.models as models
from torchvision import datasets, transforms
# EFDL:引入EFDL
import efdl.backend.torch as efdl
efdl.init(timeout=60)
torch.cuda.set_device(efdl.get_local_rank())
import argparse
parser = argparse.ArgumentParser(description='hvd_pytorch_mnist')
parser.add_argument('--data', type=str, dest='data', default='./data')
parser.add_argument('--lr', type=int, dest='lr', default=0.001)
parser.add_argument('--epoch', type=int, dest='epoch', default=90)
parser.add_argument('--step_size', type=int, dest='step_size', default=30)
parser.add_argument('--log_interval', type=int, dest='log_interval', default=10)
parser.add_argument('--batch_size', type=int, dest='batch_size', default=1)
parser.add_argument('--save_dir', type=str, dest='save_dir', default='./result')
args = parser.parse_args()
epoch_ = args.epoch
lr_ = args.lr
momentum_ = 0.9
step_size = args.step_size
log_interval = args.log_interval
batch_size = args.batch_size
model = models.resnet50(num_classes=10)
model = torch.nn.parallel.DistributedDataParallel(model.cuda(), device_ids=[efdl.get_local_rank()],
output_device=efdl.get_local_rank())
optimizer = optim.SGD(model.parameters(), lr=lr_, momentum=momentum_)
scheduler = torch.optim.lr_scheduler.StepLR(optimizer, step_size, gamma=0.1, last_epoch=-1)
# EFDL:快照恢复
start_epoch = 0
if os.path.exists(os.path.join(args.save_dir, "last.pt")):
ckpt = torch.load(os.path.join(args.save_dir, "last.pt"))
start_epoch = ckpt['epoch'] + 1
model.load_state_dict(ckpt['model'])
optimizer.load_state_dict(ckpt['optimizer'])
scheduler.load_state_dict(ckpt['scheduler'])
duplicate_data_path = './data_{}'.format(str(uuid.uuid1()))
shutil.copytree('./data', duplicate_data_path)
train_dataset = \
datasets.MNIST(duplicate_data_path, train=True, download=True,
transform=transforms.Compose([
transforms.Resize((224, 224)),
transforms.Lambda(lambda image: image.convert('RGB')),
transforms.ToTensor(),
transforms.Normalize(mean=[0.485, 0.456, 0.406],
std=[0.229, 0.224, 0.225])
]))
shutil.rmtree(duplicate_data_path)
train_sampler = torch.utils.data.distributed.DistributedSampler(train_dataset)
train_loader = torch.utils.data.DataLoader(train_dataset, batch_size=args.batch_size, sampler=train_sampler,
pin_memory=True, num_workers=8)
for epoch in range(start_epoch, epoch_):
model.train()
train_sampler.set_epoch(epoch)
for step, (data, target) in enumerate(train_loader):
data, target = data.cuda(), target.cuda()
optimizer.zero_grad()
output = model(data)
loss = F.cross_entropy(output, target)
loss.backward()
optimizer.step()
if step % log_interval == 0:
print('Train Epoch: {} [{}/{} ({:.0f}%)]\tLoss: {:.6f}\tLR: {:.6f}'.format(
epoch, step, len(train_loader),
100.0 * step / len(train_loader), loss.item(), scheduler.get_last_lr()[0]))
scheduler.step()
if not os.path.exists(args.save_dir):
os.makedirs(args.save_dir)
# EFDL:快照保存
last_model_path = os.path.join(args.save_dir, "last.pt")
torch.save({
'epoch': epoch,
'model': model.state_dict(),
'optimizer': optimizer.state_dict(),
'scheduler': scheduler.state_dict()
}, last_model_path)
# 3.3.1.4 torch.ddp搭配efdl工具(推荐)
使用原生的torch.ddp支持弹性扩缩容以及容错,只需要引入EFDL包进行初始化即可。为了支持更好地断点训练恢复,需要用户手动保存快照以及恢复快照,可使用torch.load和torch.save方法。这种断点恢复方案虽然可行,但是问题在不灵活而且很耗时。
为此,efdl提供了断点恢复工具State和DistributedSampler,分别支持内存快照缓存与定时持久化,以及更细粒度的数据读取恢复,具体用法可以参照文档第三章。
需要注意的是,在使用torch.ddp时,传入State的模型对象不可是torch.nn.parallel.DistributedDataParallel封装的。因为其本身会同步一遍模型,而为了避免快照恢复后的二次同步,只能传入torch.nn.parallel.DistributedDataParallel封装前的模型对象。如果模型封装不在主代码中,可用set_and_resotre_model等函数分开赋值,详情见文档第三章。
import math
import uuid
import shutil
import argparse
import torch.nn.functional as F
import torch.optim as optim
import torch.utils.data.distributed
import torchvision.models as models
from torchvision import datasets, transforms
parser = argparse.ArgumentParser(description='hvd_pytorch_mnist')
parser.add_argument('--data', type=str, dest='data', default='./data')
parser.add_argument('--epoch', type=int, dest='epoch', default=100)
parser.add_argument('--lr', type=int, dest='lr', default=0.001)
parser.add_argument('--step_size', type=int, dest='step_size', default=20)
parser.add_argument('--log_interval', type=int, dest='log_interval', default=10)
parser.add_argument('--batch_size', type=int, dest='batch_size', default=1)
args = parser.parse_args()
# EFDL:引入EFDL
import efdl.backend.torch as efdl
efdl.init()
torch.cuda.set_device(efdl.get_local_rank())
epoch_ = args.epoch
lr_ = args.lr
momentum_ = 0.9
step_size = args.step_size
log_interval = args.log_interval
model = models.resnet50(num_classes=10).cuda()
optimizer = optim.SGD(model.parameters(), lr=lr_ * efdl.get_world_size(), momentum=momentum_)
scheduler = torch.optim.lr_scheduler.StepLR(optimizer, step_size, gamma=0.1, last_epoch=-1)
# EFDL:声明efdl.state,用于保存关键变量以及节点间通信
state = efdl.State(model, optimizer, scheduler, epoch=0, step=0, world_size=efdl.get_world_size())
state.set_commit_interval(log_interval * 10)
model = torch.nn.parallel.DistributedDataParallel(model.cuda(), device_ids=[efdl.get_local_rank()], output_device=efdl.get_local_rank())
# EFDL:根据环境重新设置相关变量的方法
pre_world_size = state.world_size
state.world_size = efdl.get_world_size()
if state.world_size != pre_world_size and state.step != 0:
state.step = math.floor((state.step + 1) * 1.0 * pre_world_size / state.world_size)
duplicate_data_path = '{}_{}'.format(args.data, str(uuid.uuid1()))
shutil.copytree(args.data, duplicate_data_path)
train_dataset = \
datasets.MNIST(duplicate_data_path, train=True, download=True,
transform=transforms.Compose([
transforms.Resize((224, 224)),
transforms.Lambda(lambda image: image.convert('RGB')),
transforms.ToTensor(),
transforms.Normalize(mean=[0.485, 0.456, 0.406],
std=[0.229, 0.224, 0.225])
]))
shutil.rmtree(duplicate_data_path)
# EFDL: 使用efdl的sampler进行dataloader初始化,efdl的sampler可更新数据集分片以及指定迭代的起始位置
train_sampler = efdl.data.DistributedSampler(train_dataset, epoch=state.epoch, start_index=state.step * args.batch_size)
train_loader = torch.utils.data.DataLoader(train_dataset, batch_size=args.batch_size, sampler=train_sampler, pin_memory=True, num_workers=8)
# EFDL: 训练逻辑,epoch和step均与state关联,保证能够继续训练,调用state.commit保存状态
for state.epoch in range(state.epoch, epoch_):
train_sampler.set_epoch(state.epoch)
for state.step, (data, target) in enumerate(train_loader, start=state.step):
if torch.cuda.is_available():
data, target = data.cuda(), target.cuda()
state.optimizer.zero_grad()
output = model(data)
loss = F.cross_entropy(output, target)
loss.backward()
optimizer.step()
if state.step % log_interval == 0:
print('Train Epoch: {} [{}/{} ({:.0f}%)]\tLoss: {:.6f}\tLR: {:.6f}'.format(
state.epoch, state.step, len(train_loader),
100.0 * state.step / len(train_loader), loss.item(), scheduler.get_last_lr()[0]))
state.commit()
state.step = 0
state.commit()
scheduler.step()
# 3.3.2 Tensorflow Keras的EFDL最佳实践
目前tensorflow.keras只支持horovod分布式训练,使用方法只需引入efdl的包即可,其它用法不变。
from efdl.backend.horovod.tensorflow.keras import hvd
hvd.init()
# 3.3.3 Tensorflow Estimator的EFDL最佳实践
目前tensorflow只支持horovod分布式训练,使用方法只需引入efdl的包即可,其它用法不变。
from efdl.backend.horovod.tensorflow import hvd
hvd.init()
# 3.4 提交训练任务

Worker镜像:可到这里 (opens new window)获取最新的基础镜像
# torch
测试镜像:registry-haiyan.local.huya.com/machine-learn/lixiaojie1_efdl_open:python3.8_torch181_cu102_efdl200_v0.0.5 代码路径:/workspace/examples 启动命令:
- torch hvd elstic:
python3 pytorch_hvd_mnist.py - torch hvd native:
python3 pytorch_hvd_mnist_resume.py - torch ddp elstic:
python3 pytorch_ddp_mnist.py - torch ddp native:
python3 pytorch_ddp_mnist_resume.py
# tensorflow keras
TBD
# tensorflow estimator
TBD
# 3.4 EFDL挂起恢复实践
从代码修改到平台提交训练
# 3.4.1 PyTorch的挂起恢复最佳实践
# 3.4.1.1 搭配原生工具
使用原生的torch支持挂起恢复,只需要做好定期保存快照以及恢复快照即可,可使用torch.load和torch.save方法。
import os
import uuid
import shutil
import torch.nn.functional as F
import torch.optim as optim
import torch.utils.data.distributed
import torchvision.models as models
from torchvision import datasets, transforms
import argparse
parser = argparse.ArgumentParser(description='hvd_pytorch_mnist')
parser.add_argument('--data', type=str, dest='data', default='./data')
parser.add_argument('--lr', type=int, dest='lr', default=0.001)
parser.add_argument('--epoch', type=int, dest='epoch', default=90)
parser.add_argument('--step_size', type=int, dest='step_size', default=30)
parser.add_argument('--log_interval', type=int, dest='log_interval', default=10)
parser.add_argument('--batch_size', type=int, dest='batch_size', default=1)
parser.add_argument('--save_dir', type=str, dest='save_dir', default='./result')
args = parser.parse_args()
epoch_ = args.epoch
lr_ = args.lr
momentum_ = 0.9
step_size = args.step_size
log_interval = args.log_interval
batch_size = args.batch_size
model = models.resnet50(num_classes=10).cuda()
optimizer = optim.SGD(model.parameters(), lr=lr_, momentum=momentum_)
scheduler = torch.optim.lr_scheduler.StepLR(optimizer, step_size, gamma=0.1, last_epoch=-1)
# EFDL:快照恢复
start_epoch = 0
if os.path.exists(os.path.join(args.save_dir, "last.pt")):
ckpt = torch.load(os.path.join(args.save_dir, "last.pt"))
start_epoch = ckpt['epoch'] + 1
model.load_state_dict(ckpt['model'])
optimizer.load_state_dict(ckpt['optimizer'])
scheduler.load_state_dict(ckpt['scheduler'])
duplicate_data_path = './data_{}'.format(str(uuid.uuid1()))
shutil.copytree('./data', duplicate_data_path)
train_dataset = \
datasets.MNIST(duplicate_data_path, train=True, download=True,
transform=transforms.Compose([
transforms.Resize((224, 224)),
transforms.Lambda(lambda image: image.convert('RGB')),
transforms.ToTensor(),
transforms.Normalize(mean=[0.485, 0.456, 0.406],
std=[0.229, 0.224, 0.225])
]))
shutil.rmtree(duplicate_data_path)
train_loader = torch.utils.data.DataLoader(train_dataset, batch_size=args.batch_size, pin_memory=True, num_workers=8)
for epoch in range(start_epoch, epoch_):
model.train()
train_sampler.set_epoch(epoch)
for step, (data, target) in enumerate(train_loader):
data, target = data.cuda(), target.cuda()
optimizer.zero_grad()
output = model(data)
loss = F.cross_entropy(output, target)
loss.backward()
optimizer.step()
if step % log_interval == 0:
print('Train Epoch: {} [{}/{} ({:.0f}%)]\tLoss: {:.6f}\tLR: {:.6f}'.format(
epoch, step, len(train_loader),
100.0 * step / len(train_loader), loss.item(), scheduler.get_last_lr()[0]))
scheduler.step()
if not os.path.exists(args.save_dir):
os.makedirs(args.save_dir)
# EFDL:快照保存
last_model_path = os.path.join(args.save_dir, "last.pt")
torch.save({
'epoch': epoch,
'model': model.state_dict(),
'optimizer': optimizer.state_dict(),
'scheduler': scheduler.state_dict()
}, last_model_path)
# 3.4.1.2 搭配efdl工具(推荐)
虽然使用原生的工具也可以进行挂起恢复,但同样存在保存不够灵活、保存耗时高、保存周期长的问题。
为此,可借用efdl提供的断点恢复工具State和DistributedSampler,分别支持内存快照缓存与定时持久化,以及更细粒度的数据读取恢复,具体用法可以参照文档第三章。
import math
import uuid
import shutil
import argparse
import torch.nn.functional as F
import torch.optim as optim
import torch.utils.data.distributed
import torchvision.models as models
from torchvision import datasets, transforms
parser = argparse.ArgumentParser(description='hvd_pytorch_mnist')
parser.add_argument('--data', type=str, dest='data', default='./data')
parser.add_argument('--epoch', type=int, dest='epoch', default=100)
parser.add_argument('--lr', type=int, dest='lr', default=0.001)
parser.add_argument('--step_size', type=int, dest='step_size', default=20)
parser.add_argument('--log_interval', type=int, dest='log_interval', default=10)
parser.add_argument('--batch_size', type=int, dest='batch_size', default=1)
args = parser.parse_args()
# EFDL:引入EFDL
import efdl.backend.torch as efdl
epoch_ = args.epoch
lr_ = args.lr
momentum_ = 0.9
step_size = args.step_size
log_interval = args.log_interval
model = models.resnet50(num_classes=10).cuda()
optimizer = optim.SGD(model.parameters(), lr=lr_ * efdl.get_world_size(), momentum=momentum_)
scheduler = torch.optim.lr_scheduler.StepLR(optimizer, step_size, gamma=0.1, last_epoch=-1)
# EFDL:声明efdl.state,用于保存关键变量以及恢复之前保存的变量
state = efdl.State(model, optimizer, scheduler, epoch=0, step=0)
state.set_commit_interval(log_interval * 10)
duplicate_data_path = '{}_{}'.format(args.data, str(uuid.uuid1()))
shutil.copytree(args.data, duplicate_data_path)
train_dataset = \
datasets.MNIST(duplicate_data_path, train=True, download=True,
transform=transforms.Compose([
transforms.Resize((224, 224)),
transforms.Lambda(lambda image: image.convert('RGB')),
transforms.ToTensor(),
transforms.Normalize(mean=[0.485, 0.456, 0.406],
std=[0.229, 0.224, 0.225])
]))
shutil.rmtree(duplicate_data_path)
# EFDL:使用efdl.data.DistributedSampler进行更细粒度的恢复
train_sampler = efdl.data.DistributedSampler(train_dataset, epoch=state.epoch, start_index=state.step*args.batch_size)
train_loader = torch.utils.data.DataLoader(train_dataset, batch_size=args.batch_size, sampler=train_sampler, pin_memory=True, num_workers=8)
# EFDL: 训练逻辑,epoch和step均与state关联,保证能够继续训练,调用state.commit保存状态
for state.epoch in range(state.epoch, epoch_):
train_sampler.set_epoch(state.epoch)
for state.step, (data, target) in enumerate(train_loader, start=state.step):
if torch.cuda.is_available():
data, target = data.cuda(), target.cuda()
state.optimizer.zero_grad()
output = model(data)
loss = F.cross_entropy(output, target)
loss.backward()
optimizer.step()
if state.step % log_interval == 0:
print('Train Epoch: {} [{}/{} ({:.0f}%)]\tLoss: {:.6f}\tLR: {:.6f}'.format(
state.epoch, state.step, len(train_loader),
100.0 * state.step / len(train_loader), loss.item(), scheduler.get_last_lr()[0]))
state.commit()
state.step = 0
state.commit()
scheduler.step()
# 3.4.2 Tensorflow Keras的挂起恢复最佳实践:
TBD
# 3.4.3 Tensorflow Estimator的挂起恢复最佳实践:
TBD
# 3.4.4 提交训练任务
任务提交跟4.4的EFDL弹性训练一样,只是最小Worker数和最大Worker数均设置为1,模式选择Horovod或Pytorch Distributed都可以。
# 3.5 EFDL碎片化调度实践
EFDL碎片化调度自动根据集群状况,将单容器8卡的训练拆分为两个容器进行训练,容器卡数之和为8卡。
目前碎片化调度只支持Pytorch DDP模式,使用前仅需对代码和启动方式进行少量修改,然后使用特定的启动方式即可。
注意,碎片化调度需要efdl>=2.0.6,在启动命令安装efdl是无效的。
# 3.5.1 PyTorch DDP的碎片化调度最佳实践
镜像预先安装efdl>=2.0.6
pip3 install efdl --extra-index https://npm.huya.info/repository/pypi-huya/simple -i https://pypi.tuna.tsinghua.edu.cn/simple
代码修改需要从原生的初始化方法改为efdl的初始化方法。
import torch.distributed as dist
# dist.init_process_group()
import efdl.backend.torch as efdl
efdl.init()
启动命令需要从原生的封装启动改为直接启动。
如果程序内部接收了local_rank命令行参数,请转为从efdl.get_local_rank()取。
# python3 -m torch.distributed.launch --nproc_per_node 8 train.py
python3 train.py
最后就是任务启动,主要有以下三点:
- 选择
EFDL弹性训练(PyTorch Distributed)模式。 - 最小Worker数和最大Worker数固定为
1。 - Worker 资源组选择带
seperate字样的配置。

# 4 如何在托管训练跑LLaMA-Factory、ColossalAI等框架的分布式训练
前提:请在镜像中提前安装好efdl库,这个库的安装不能写在启动命令,必须提前装在镜像中
在平台托管训练设置如下:
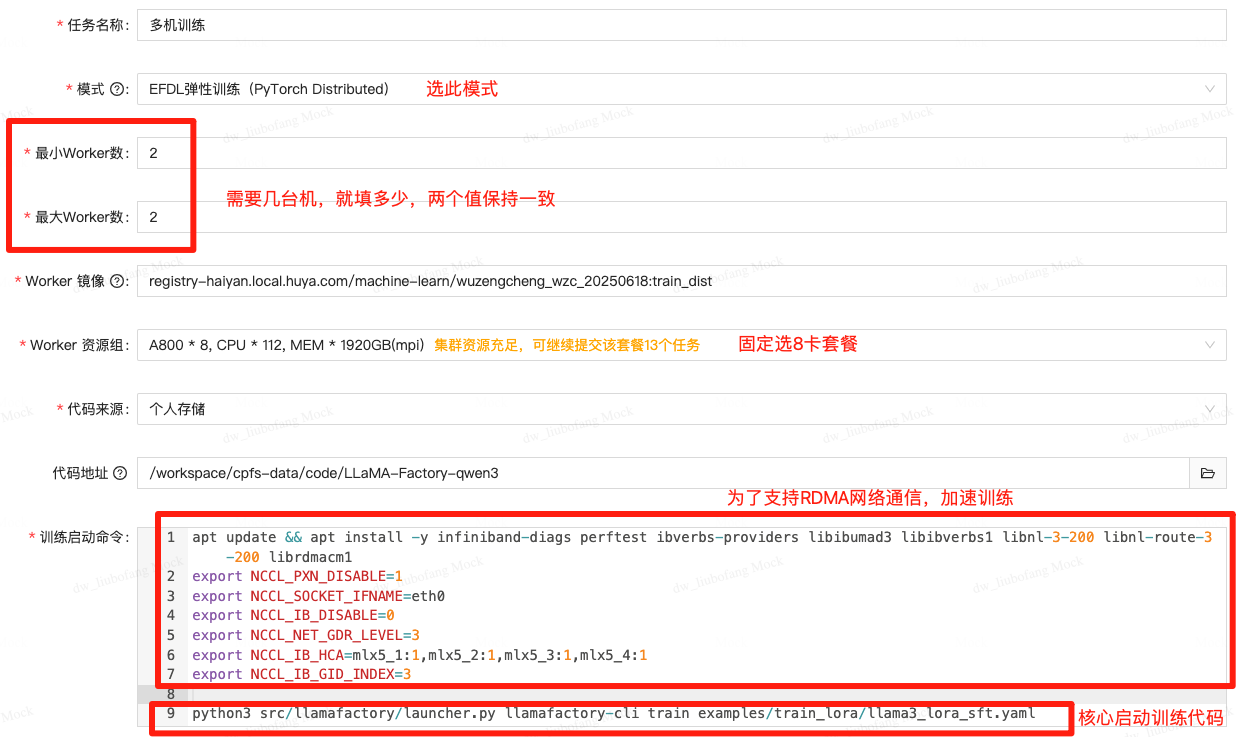
其中,为了支持RDMA加速训练,需要添加如下命令:(仅火山上海A800支持此功能,其它卡请忽略)
apt update && apt install -y infiniband-diags perftest ibverbs-providers libibumad3 libibverbs1 libnl-3-200 libnl-route-3-200 librdmacm1
export NCCL_PXN_DISABLE=1
export NCCL_SOCKET_IFNAME=eth0
export NCCL_IB_DISABLE=0
export NCCL_NET_GDR_LEVEL=3
export NCCL_IB_HCA=mlx5_1:1,mlx5_2:1,mlx5_3:1,mlx5_4:1
export NCCL_IB_GID_INDEX=3
注:可以将这个安装和环境变量设置提前打进镜像里,这样子就不需要每次启动都装一遍,当然留在启动命令也可以。
然后需要修改启动命令,这里分别解释:
# LLaMA-Factory
原来官方给的启动命令如下,需要分别在多机执行:
FORCE_TORCHRUN=1 NNODES=2 NODE_RANK=0 MASTER_ADDR=192.168.0.1 MASTER_PORT=29500 \
llamafactory-cli train examples/train_lora/llama3_lora_sft.yaml
FORCE_TORCHRUN=1 NNODES=2 NODE_RANK=1 MASTER_ADDR=192.168.0.1 MASTER_PORT=29500 \
llamafactory-cli train examples/train_lora/llama3_lora_sft.yaml
在海聪上,只需更改为如下即可:
python3 src/llamafactory/launcher.py examples/train_lora/llama3_lora_sft.yaml
# ColossalAI
原来官方给的启动命令如下:
colossalai run --hostfile path-to-host-file --nproc_per_node 8 lora_finetune.py --pretrained path-to-DeepSeek-R1-bf16 --dataset path-to-dataset.jsonl --plugin moe --lr 2e-5 --max_length 256 -g --ep 8 --pp 3 --batch_size 24 --lora_rank 8 --lora_alpha 16 --num_epochs 2 --warmup_steps 8 --tensorboard_dir logs --save_dir DeepSeek-R1-bf16-lora
只需更改为如下即可:
python3 lora_finetune.py --pretrained path-to-DeepSeek-R1-bf16 --dataset path-to-dataset.jsonl --plugin moe --lr 2e-5 --max_length 256 -g --ep 8 --pp 3 --batch_size 24 --lora_rank 8 --lora_alpha 16 --num_epochs 2 --warmup_steps 8 --tensorboard_dir logs --save_dir DeepSeek-R1-bf16-lora
# Swift (ModelScpoe)
原来官方给的启动命令如下:
export NNODES=${EFDL_NUM_MAX_WORKERS}
export NPROC_PER_NODE=8
swift sft --model /path/to/model --train_type full --model_type qwen2_5 --template default --xxx省略
只需更改为如下即可:
export NNODES=${EFDL_NUM_MAX_WORKERS}
export NPROC_PER_NODE=8
python3 swift/cli/sft.py --model /path/to/model --train_type full --model_type qwen2_5 --template default --xxx省略
# Accelerate (HuggingFace)
启动命令参考:
while [ "$LOCAL_RANK" != "0" ]; do
sleep 10
done
accelerate launch \
--config_file your_config.yaml \
--main_process_ip $MASTER_ADDR \
--main_process_port $MASTER_PORT \
--machine_rank $((RANK / 8)) \
--num_processes $WORLD_SIZE \
--num_machines $((WORLD_SIZE / 8)) \
examples/wanvideo/model_training/train.py --xxx剩余参数
# 核心要点
在海聪启动多机分布式训练时,平台会自动给每个进程注入相应的环境变量,主要包括:
- WORLD_SIZE:总GPU数
- RANK:每个GPU的编号,全局
- MASTER_ADDR:master的IP
- MASTER_PORT:master的端口
目前所有多机分布式训练框架,都是万变不离其宗,根据这几个环境变量来通信